Исследование задач и методов разработки информационно-аналитических инструментов поддержки принятия решений по стратегическим вопросам военной безопасности
Полковник В. В. ЩИПАЛОВ,
кандидат технических наук
При практически необозримом объеме, разнородности и динамике
развития политических, экономических, социальных и
военных факторов, характеризующих развитие обстановки в современном
мире, выполнение многих задач стратегического
планирования, оценки и принятия стратегических решений
становится трудоемким сложным процессом. Каждый день на
высшем, стратегическом военно-политическом уровне руководства
России, а также на нижестоящих уровнях структуры управления
страной принимается множество решений по различным
вопросам, касающимся планирования, контроля, распределения.
Почти всегда обстоятельства требуют, чтобы решения эти
принимались быстро, и при этом являлись оптимальными.
Причем для ответственного лица, принимающего решение,
чрезвычайно важно иметь возможность заранее или впоследствии
обосновать оптимальность принятого решения.
Опыт деятельности в сфере подготовки проектов решений
показывает, что в ходе проделанной к настоящему времени работы
по подготовке данных накоплен большой объем информации,
получены уникальные знания и разработаны различные
показатели, способные характеризовать текущую ситуацию в
мире с точки зрения рассматриваемых задач управления. Однако,
как правило, весь этот ценнейший информационный материал
хранится в основном в памяти соответствующих специалистов
и в лучшем случае в условно систематизированном виде в
их личных документах. Принимаемые решения в большой степени
базируются на опыте и персональных знаниях лиц, принимающих
решения, поэтому успех и ошибки существенно зависят
от личностного фактора. Поэтому формализация всего объема информации для обеспечения принятия решения и преемственности
таких знаний является важнейшей задачей.
Высшее военно-политическое руководство России, с одной
стороны, осознает, что существуют современные информационно-аналитические технологии, позволяющие поднять на новый
уровень информационно-аналитическое обеспечение процесса
подготовки и принятия решений. С другой стороны, высшее
военно-политическое руководство России уже накопило в
своей базе данных достаточное количество информации, которая,
по сделанным предварительным оценкам, может быть использована
как основа для обеспечения применимости аналитических
методов.
Рассмотрим возможность адаптации существующих (а если
необходимо — создания новых) технологий для решения практических
задач планирования и принятия стратегических решений
высшим военно-политическим руководством России. Рассмотрим
также задачу оценки и отбора первичной информации
с целью наиболее эффективного ее использования и вопросы
применения методов информационно-аналитической поддержки
решений конкретных задач, возникающих в процессе деятельности
высшего военно-политического руководства России;
разработки моделей и методик их решения.
Объектом исследования является некоторая система S, состояние
которой s характеризуется фиксированным набором
бинарных признаков
Таким образом, для каждого состояния s признак pk(s) может
принимать два значения 0 или 1. Набор таких признаков будем
называть экспертной оценкой состояния системы s (ЭОС). Кроме
этого, мы выделим отдельно еще один бинарный признак
po(s), зависящий от состояния системы, который в дальнейшем
будем называть стратегическим решением (CP), принятым на
основании экспертной оценки системы. Предположим, что
имеется набор состояний si,S2,...,Sm и матрица значений всех
признаков для всех состояний
Поставим следующую задачу. На основании имеющейся базы
данных (1) разработать стратегию, которая позволяет по набору
экспертных оценок возникшего состояния системы s принять
стратегическое решение po(s).
Рассмотрим содержание и методику ведения исследований
по анализу применения методов информационно-аналитической
поддержки принятия решений высшим военно-политическим
руководством России. Используемая методика исследования
лежит в рамках классического системного анализа и включает
следующие этапы:
определение ограничений предметной области;
построение модели системы;
анализ альтернатив реализации;
демонстрационное моделирование.
На первом этапе конкретизируются формулировки задач, которые
должна решать система поддержки принятия решений.
Постановка, сделанная в рамках предварительных собеседований
со специалистами по подготовке принятия решений высшим
руководством страны, требует уточнений и детализации. С
этой целью необходимо проведение серии встреч со специалистами
функциональных подразделений высшего военно-политического
руководства России, в результате которых должна быть
получена и проанализирована первичная информация о сути
поставленных задач и сформулирован их уточненный список.
Второй этап заключается в анализе конкретных методов и
методик решения задачи стратегического прогнозирования, которые
позволяют в рамках описываемых моделей решать сформулированные
задачи.
На третьем этапе предполагается провести реальное моделирование
по разработанным методиками с использованием отобранных
методов для задач принятия стратегических решений,
для которых будут представлены данные по реальным экспертным
оценкам состояния системы.
На четвертом этапе осуществляется выявление зависимости
между признаками, входящими в ЭОС. Данная процедура описывается
в одном из разделов ниже.
Проведем анализ экспертных оценок состояния системы.
Опишем общий подход, в рамках которого будет проводиться анализ. Считаем, что состояние системы описывается некоторыми
числовыми показателями ЭОС.
Основной постулат, на котором основан анализ данных в рамках
этой задачи, заключается в том, что имеется реальная зависимость
между признаками ЭОС и выходным признаком СР.
Исходя из этого, реализуются следующие этапы проведения
анализа: для известных в прошлом состояний системы исследуется
зависимость значений интересующего нас показателя —
например, «уровень готовности экономики и Вооруженных Сил
России к отражению вооруженной агрессии со стороны развитых
государств» или «степень угрозы развязывания войны против
России» — от значений соответствующих показателей, а
также выявляются закономерности между различными показателями
ЭОС, если они есть. Строится модель, выявляющая типичные
зависимости между отдельными показателями системы
ЭОС и между показателями ЭОС и основным показателем СР.
Регистрируются все отклонения от модельного поведения (аномалии),
имевшие место на содержащихся в базе данных ЭОС, и
соответствующие им значения используемых показателей.
Если собранные значения показателей соответствуют зарегистрированным
на предыдущем аномалиям — это основание для
выдачи соответствующего предупреждения по показателям и
самим состояниям системы, на которых эти аномалии зарегистрированы.
Модель может корректироваться при вновь образующихся
состояниях системы.
Рассмотрим методы решения задач и методику их использования,
а также выберем методы анализа и проведем анализ задачи
принятия стратегических решений.
Для этого перейдем к описанию трех возможных методов решения
задачи поиска функциональных зависимостей одних
групп эмпирически заданных показателей, определяющих принятие
стратегического решения при данном состоянии системы,
от других групп показателей, характеризующих это состояние.
В основе каждого из этих методов лежит гипотеза, что такая зависимость
существует.
Первый метод является хорошо известной моделью многомерной
линейной регрессии, и ее обобщения на нелинейные случаи. В этом случае параметры функции, описывающей нужную
нам закономерность, определяются методом наименьших
квадратов. Линейная модель регрессии во многих случаях дает
хорошие результаты. В том случае, когда матрицы систем уравнений
для искомых коэффициентов регрессии будут плохо
обусловлены, имеются различные подходы корректирования
модели (например, введение дополнительных фиктивных параметров
регрессии). Метод линейной регрессии может быть выбран
в качестве основного метода моделирования.
Далее будет изложена методика применения этого метода, с
простыми примерами, позволяющими быстро понять суть
практического его применения.
Второй метод является типичным методом распознавания. В
своем простейшем виде этот метод легко реализуем и менее всего
связан с какими бы-то ни было ограничениями. По существу,
этот метод может служить вспомогательным инструментом для
основного метода. Простота реализации позволяет использовать
его для настройки основного метода. С помощью этого метода,
например, имеется возможность выявлять состояния системы,
имеющиеся в базе данных, которые по каким-либо причинам
дают аномальные выбросы. Другой его возможностью
может служить ориентировочная оценка наличия линейных
трендов по отдельным показателям.
Третий метод является одним из прикладных результатов алгебраической
теории информации. Этот метод основан на расчетах
меры информативности одних показателей ЭОС по отношению к
другим показателям. В любом наборе данных или параметров
можно выявлять информативные зависимости одних параметров
от других. Характер этих зависимостей и их величины рассчитываются
и исследуются в рамках этой модели. Объектами исследования
являются состояния системы, каждое из которых характеризуется
показателями (в дальнейшем именуемыми признаками)
ЭОС. Результатом моделирования является показатель, определяющий
стратегическое решение. Этот показатель может считаться
бинарным, т.е. принимающим значение да/нет (0 или 1).
Предварительный анализ применения этих методов показал,
что в качестве основного необходимо взять первый из перечисленных.
Действительно, как уже было замечено, регрессионная модель
дает хорошие результаты в значительном числе случаев.
Это объясняется следующими обстоятельствами:
метод обладает развитым аппаратом, позволяющим корректировать
модель — для метода имеются опробованные критерии
проверки гипотез, положенных в его основу;
в случае несостоятельности этих гипотез, имеются альтернативные
пути коррекции данного метода как в направлении
усложнения положенной в основу модели зависимости, так и в
направлении селекции или отбраковки исходных данных, используемых
для анализа;
регрессионные методы обладают хорошими статистическими
свойствами;
простота математических выводов делает интуитивно понятной
«физический смысл» производимых выкладок, что в
свою очередь обеспечивают прозрачную и наглядную интерпретацию
результатов моделирования.
Ниже будет изложена методика применения регрессионных
методов применительно к нашей предметной области.
Третий из описанных выше методов предполагается использовать
в процессе дальнейшего развития аналитического аппарата
подсистемы для частных случаев, не поддающихся регрессионному
анализу. В целом потенциальная необходимость использования
третьего метода обусловлена следующими обстоятельствами:
метод хорошо зарекомендовал себя как при решении задач
геологоразведки, так и некоторых других, и нет видимых причин,
позволяющих отличать эти задачи от задач нашей предметной
области;
метод является отличным от экономико-статистических
методов решения подобных задач, что само по себе является
важным обстоятельством;
метод позволяет анализировать исходные данные в двух
важных аспектах: оценивать их значимость с точки зрения влияния
на конечный показатель; второе анализировать исходные
данные с точки зрения их взаимной зависимости;
метод позволяет на основе имеющихся показателей строить
более информативные и более сложные показатели с цель
дальнейшего их использования в задаче моделирования;
метод имеет гибкую систему настроек, позволяющую правильно
ориентировать его на поставленную задачу.
Возможности третьего из рассмотренных методов (в перспективе
равноценного с методом регрессии) объясняют подробное
изложение в дальнейшем соответствующего математического
аппарата.
Предлагается следующая методика поиска и верификации
закономерностей в исходных данных с использованием ранее
сформулированного основного метода.
Прежде всего делается ряд предположений о характере зависимостей
в исходных данных. При проведении анализа подразумевается,
что искомая функциональная зависимость существует.
Далее предположения формулируются в виде ряда формальных
гипотез, которые будут подвергнуты проверке. Для того
чтобы провести формальный анализ данных, гипотезы должны
быть сформулированы в виде математических зависимостей
одних переменных от других. Вид зависимости должен быть
описан в регрессионном уравнении, которое будет оцениваться
на имеющихся данных. В результате проверки гипотезы методами
теории вероятностей и регрессионного анализа она может
быть отвергнута или не отвергнута в соответствии с заранее заданными
критериями. Кроме того, в процессе анализа будут
получены численные оценки зависимостей и статистика, характеризующие
точность используемых методов. В случае неудовлетворительной
работы метода должны быть модифицированы
как регрессионное уравнение, так и вероятностная методика
его оценки.
Построим базовую модель, в основе которой лежит регрессионный
анализ пространственных данных и временных рядов.
На начальном этапе предполагается использовать регрессионные
модели с одним уравнением. По основному набору параметров
будет использовано линейное приближение оцениваемой
функции. Такой метод позволяет наиболее легко интерпретировать
полученные результаты и использовать их при прогнозировании.
В случае, если полученные нами статистики позволяют
оценить степень соответствия построенной модели исходным
реальным данным (подробнее об этом ниже) и графическое
представление данных свидетельствует о нелинейной зависимости, в регрессионных уравнениях будут дополнительно использованы
квадратичные, а возможно и другие функции. Тестирование
каждой гипотезы будет заключаться в поиске коэффициентов
регрессионного уравнения или системы уравнений, отвечающих
этой гипотезе.
Рассмотрим в качестве примера следующую гипотезу: стратегическое
решение «степень угрозы развязывания войны против
России» растет с изменением экспертной оценки состояния системы
«превышение заданной концентрации войск потенциального
противника на заданном участке границы России» с
«нет» на «да», с изменением другой экспертной оценки с «нет»
на «да», третьей экспертной оценки с «нет» на «да» и четвертой
экспертной оценки с «нет» на «да». Регрессионное уравнение
для проверки этой гипотезы может иметь следующий вид:
где Y — уровень угрозы, В — превышения порога концентрации
войск противника на границе, С, D, Е — соответственно
вторая, третья и четвертая экспертная оценка. В соответствии с
нашей гипотезой коэффициенты βι, рз, и β4 положительные,
а β2 — отрицательный. В данном случае уровень угрозы — это зависимая
переменная, а экспертные показатели — независимые
переменные. В результате тестирования уравнения на имеющихся
данных, мы получим численные коэффициенты для зависимостей
и статистики, свидетельствующие о силе связи между
зависимыми и независимыми параметрами (значимость коэффициентов).
В теории принято рассматривать только те зависимости,
у которых значимость коэффициентов находится на
уровне менее 1, 5 или 10 %. Так, значимость в 1% говорит о том,
что вероятность получить имеющиеся данные при отсутствии
зависимости между параметрами меньше 1 % (в этом случае мы
говорим, что гипотеза не отвергается на уровне значимости в
1%). Если значимость в 10% свидетельствует о большой вероятности
наличия связи, то значимость в 1% интерпретируется как
безусловное наличие связи между переменными. Вместо величины
значимости может использоваться так называемая t-статистика, вычисляемая по формуле:
где β — оценка параметра, а — выборочная дисперсия оценки.
Статистика имеет распределение Стьюдента с п-2 степенями
свободы, где η — это количество наблюдений.
Кроме того, статистика R2, вычисляемая при оценке регрессионного
уравнения, позволит нам узнать, какую долю вариации
зависимой переменной (в данном примере явки избирателей)
объясняют независимые переменные. Статистика R2 имеет распределение
с п-2 степенями свободы и вычисляется по формуле
где в числителе стоит объясненная часть дисперсии зависимой
переменной (квадрат разности реального и предсказанного
значения переменной), а в знаменателе — необъясненная часть
(квадрат разности предсказанного и среднего значения переменной).
Чем больше значение в данной статистике, тем точнее
данные соответствуют выбранной модели. В итоге, используя
описанные средства, мы сможем понять, какую долю принятия
решения о повышении угрозы объясняют выбранные нами переменные.
Более того, дополнительные тесты позволят нам узнать
подобную статистику для каждой независимой переменной.
В результате мы сможем сделать вывод о том, какие из положений
описанной гипотезы принимаются, а какие отвергаются,
и получить количественные значения зависимостей. При
принятии стратегического решения по прогнозируемому предстоящему
состоянию системы, полученные коэффициенты и
статистики позволят нам найти ожидаемое значение уровня угрозы,
построить доверительный интервал (к примеру, построить
95% доверительный интервал — значит найти такие границы, в
которые найденное значение готовности попадет с вероятностью
95%), а также найти другие интересующие нас величины.
Приведенный пример является только иллюстрацией предлагаемой
методики. Только непосредственная реальная работа с
данными может дать ответ на вопрос, какие из переменных необходимо включать в регрессию. При работе с данными часто
возникают проблемы, связанные с тем, что имеющиеся значения
выбранных нами переменных не соответствуют спецификации
модели. К примеру, наличие сильной корреляции между
различными экспертными оценками состояния системы приведет
к тому, что наша модель будет не идентифицируема. В этом
случае, нам придется либо использовать более сложные по сравнению
с методом наименьших квадратов способы оценивания,
либо изменить используемый набор переменных. К наиболее
вероятным дополнениям и видоизменениям базовой модели
следует отнести такие модификации модели, в которых будет
отслеживаться изменение коэффициентов со временем и учитываться
индивидуальные характеристики каждого состояния
системы, не наблюдаемые в наших переменных. Окончательный
выбор методики осуществляется в процессе работы с данными
и определяется тем, какой модели имеющиеся данные
подходят в наибольшей степени.
Приведем описание расчетной части предлагаемого в качестве
основного метода регрессии. Как уже отмечалось выше, схема
линейной регрессии может оказаться недостаточной для получения
надежных и устойчивых результатов, поэтому здесь
приводятся расчетные уравнения коэффициентов регрессии в
более общем случае.
Обозначим вектор показателей ЭОС системы через х =
= ( x i , Х2, Хт), т-число показателей ЭОС системы. Исследуемый
показатель CP обозначим у. Искомая зависимость ищется в
виде функции у = f (р,х), где р = (pi, p2,...,pm) вектор варьируемых
параметров (весов). Мы будем предполагать, что функция f (р,х)
линейна по р, т.е. представима в виде
а(х) — некоторые функции.
Эмпирически заданные значения показателя ЭОС системы
обозначим у*. Метод наименьших квадратов состоит в задаче
поиска весовых коэффициентов р, минимизирующих сумму
квадратов
Используя необходимое условие экстремума, получим систему
уравнений
или
подставляя выражение для f в полученную формулу имеем
откуда получаем систему алгебраических линейных уравнений
для определения весовых коэффициентов р
Коэффициенты этой матрицы обозначим
Система (2) для расчета весов принимает вид
В линейном случае регрессии а(х) = х. Если в силу каких-либо
причин линейная модель оказывается недостаточно точной,
следует рассматривать квадратичную модель, в которую помимо
слагаемых а(х)=х, будут входить слагаемые, содержащие члены
второго порядка xpxq.
Приведем описание технологии расчетов по второму из рассматриваемых
методов.
Обозначим вектор показателей ЭОС системы через х =
= (xi, Х2,..., Хт). Исследуемый показатель CP обозначим через у.
Рассмотрим m-мерное евклидово пространство Rm с метрикой,
определяемой скалярным произведением
где ρ = ( p i , рг, pm) — вектор весов. Мы предполагаем, что
показатель у(х) может принимать лишь два значения, 1 или О
(например, начать заблаговременную подготовку к войне или
нет). Эмпирические данные по всем состояниям, ранее занесенным
в базу данных, определяют множество X в пространстве
Rm, состоящее из п точек (по числу описанных состояний системы).
Каждой точке этого множества сопоставлено значение О
или 1 показателя у. Этот показатель для подлежащего исследованию
состояния системы с набором показателей х определяется
равенством
где г выбрано так, что
Находя следующую по расстоянию точку к х с противоположным
значением у(х), можно вычислить оценку сделанного
прогноза. Например, если следующая, ближайшая к х точка Xs и
y(xs)=l-y(xr), то оценку прогноза следует взять равной величине
Если вторая ближайшая точка имеет то же значение
у(х5)=у(хг), то ищется следующее по расстоянию состояние системы, пока не найдем противоположное значение. Само собой,
количество одноименных соседей также будет влиять на оценку
показателя у в положительную сторону.
Рассмотрим третий (альтернативный) метод моделирования,
основанный на использовании комбинаторных формул расчета информативности
показателей ЭОС. Для этого случая приводится
расчетная часть метода, базирующаяся на комбинаторных формулах
вычисления информативности нужных показателей признаков.
Для расчетов по этой методике признаки должны принимать
целочисленные значения (точнее, натуральные значения) в некотором
фиксированном диапазоне натуральных чисел. Процедура
представления имеющихся признаков состояния в целочисленном
виде носит название квантования признаков. Вопросы
оптимального выбора квантования в данной работе затрагиваться
не будут. Мы здесь отметим лишь один принцип
квантования, принцип «вариационного ряда». Для всех признаков
можно выбрать диапазон их изменения после процедуры
квантования равным [0,s-l] (например, s=32), так что после
квантования каждый признак сможет принимать лишь значения
0,l,...,s-l. Заметим, что чем больше число градаций имеет
признак, тем больше его информативность. С другой стороны,
чрезмерная детализация также не желательна. Для конкретного
признака, исходя из базы данных, вначале выбирается диапазон
изменения его значений. Все возможные значения этого признака
располагают в возрастающем порядке. В полученном ряде
выбирают диапазоны для квантования в количестве s вида
желательно так, чтобы в каждый из предлагаемых полуинтервалов
попадало приблизительно одинаковое число значений данного
признака. Для каждого из признаков этот набор полуинтервалов
будет свой. Известно, что именно при таком выборе
будет потеряно минимальное количество информации. Если
признак U = (uo, ui, ш), то результатом квантования будет
признак X = (хо, xi, Хк), где xj = m, uje (qm, qm+1].
Для квантованных значений признаков строится информационная
матрица (таблица 1):
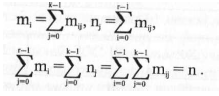
Здесь k — число признаков, г — число состояний системы, у
принимает значения 0 или 1. Значение каждого za является целочисленным
из диапазона [0,s-1 ]. В обучающую выборку включают
часть состояний системы, остальные используются для настройки
параметров системы распознавания. Следующим шагом
является построение матрицы переходов для каждого из к
признаков.
Рассмотрим некоторый признак X. Этому признаку соответствует
определенный столбец в информационной матрице. Для
вычисления информационности данного признака составляется
матрица переходов значений признака X в значения признака
Y (таблица 2).
Здесь к - 2 , г-32 ( число квантов ), mu - число переходов i -
го значения признака X в j - e значение признака Υ (0 или 1):
Информативность признака X равна количеству информации,
содержащейся в этом признаке относительно основного
признака Υ Эта величина обозначается Ιο(Χ:Υ) и вычисляется по
следующим формулам (в действительности, в качестве информативности
признака мы будем использовать нормированное
значение этой информативности Info(X)):
Через log здесь обозначается логарифм по основанию 2. Некоторые
признаки могут повторять друг друга. Характеристикой
информативной близости признаков служит информационное
расстояние между признаками. Это расстояние определяется по
формуле р(ХР, Хч) = (Io (Xp/Xq) + Io (Xp/Xq))/2. Если расстояние
«мало», то признаки «сильнее» зависимы, т.е. повторяют друг
друга. Матрицы переходов значений признака Хр в значения
признака Xq и наоборот, необходимые для вычисления указанных
величин, строятся по той же схеме. Число столбцов таких матриц будет равно 32 вместо двух. На этом этапе вводится первый
параметр настройки конструируемого метода распознавания,
параметр а. На основании этого параметра отбрасываются
из дальнейшего рассмотрения все признаки с информативностью,
не превосходящей этого параметра.
Далее рассмотрим подробнее методику распознавания или,
что одно и то же, методику определения показателя у по данному
набору исходных признаков. Отдельно взятые признаки
из исходных имеют каждый в отдельности незначительную информативность
по отношению к основному признаку Y Поэтому
на простых признаках строятся сложные признаки,
представляющие собой прямые произведения простейших
признаков. Если два из таких признаков ХР и Xq независимы
(информационное расстояние не мало), то информативность
сложного признака ХР ® Хч будет не меньше суммы информативности
составляющих признаков. Вводится второй параметр
настройки р, дающий порог рассмотрения сложных признаков
второго порядка. Сначала найдем все двойные признаки
с превышением по информативности числа р\ Для двойных
признаков с меньшей информативностью, как правило, строятся
сложные признаки третьего порядка с тем, чтобы превысить
порог р. Для построенных таким образом сложных признаков
второго и третьего порядка вычисляются матрицы перехода
в основной признак Y, которые применяются на следующих
этапах распознавания. Таким образом, результатом данного
этапа распознавания является набор сложных признаков
и их матриц переходов в Y.
Рассмотрим пространство стандартных признаков, метрику
Хэмминга, на втором этапе распознавания. На этом этапе для
каждого из отобранных на предыдущем этапе признаков будет построен
новый «стандартный» признак. Пусть у i-й военно-стратегической
обстановки сложный признак ХР ® Хч ® Хг относится к
разряду выбранных в предыдущем пункте. Вводим третий целочисленный
параметр настройки g—1,2,3,.... Рассмотрим i-ю строку
матрицы переходов признака ХР ® Хч ® Хг и предположим, что значение
этого признака равно (zip, 1 больше ч, &)•; в матрице переходов признака
ХР ® Xq® Хг имеется строка, соответствующая этому значению
сложного признака; в этой строке имеется два значения Со, С/ числа переходов данного значения сложного признака в О и в 1.
Предположим, что максимальное из этих значений Си Если С/ — Со
меньше у, то значением нового признака считается пробел (отказ от
распознавания по данному признаку). В противном случае значение
нового признака полагается равным 1. Параметр у определяет
степень доверия к данному признаку. Если в этом случае Ci меньше Сои
Со — Ci меньше у, то значение нового признака полагается равным 0 (а не
1, т.е. то значение, в которое переходит соответствующий признак).
Размерность нового пространства признаков равно числу
отобранных сложных признаков. Метрика Хэмминга определяется
для двух векторов (строк полученной новой информационной матрицы),
как количество координат, значения которых различны для
взятых векторов (пробел будет сравниваться только с числовым
значением и это будет считаться как различие координат). Окончательный
шаг в распознавании состоит в следующем. Для взятого
контрольного объекта производится пересчет его первичных
признаков в «пространство» Хэмминга. Полученный вектор новых
признаков сравнивается по метрике Хэмминга с двумя стандартными
векторами 0=(0,0,...,0), 1=(1,1,..., 1), ближайший вектор дает
распознанное значение признака Y.
Целью статьи является уточнение списка информационно-аналитических задач, необходимых для разработки стратегии
принятия решений, разработка методов оценки состава информации,
используемой для решения этой задачи, подбор аналитических
методов, способных работать на основе этой информации;
подбор аналитических методов, позволяющих решать
упомянутые задачи, а также разработка методик их применения.
В результате работы в данном направлении можно получить
список информационно-аналитических задач, подобрать необходимые
методы решения рассмотренных задач и разработать
методики их применения.
Рассматриваемые в статье модели принятия стратегических
решений имеют целью обеспечение достаточной степени достоверности
результатов решения аналитических задач. Описываемые
методы и методики применимы для использования с целью
моделирования процесса принятия решения по заданной
группе бинарных показателей, принятых для описания состояния
системы.
В перспективе предлагаемые методы и методики могут быть
использованы на различных уровнях управления и для разных
по масштабам задач.
1. Гоппа В.Д. Введение в алгебраическую теорию информации. М.:
Наука, 1995.
2. Финингоф Б.М. Сжатие дискретной информации // Проблемы
передачи информации. 1967. Т.З. №3. С. 26 — 36.
3. Финингоф Б.М. Оптимальное кодирование при меняющейся и
неизвестной статистике сообщений // Проблемы передачи информации.
1966. Т.2. №2. С. 3 - 11.
4. Васильев Ф.Г. Анализ геохимических факторов модели распознавания
образов. М.: МГРИД987.
5. Бонгард М.М. Проблема узнавания. М.: Наука, 1967.
6. Борейко И.С, Гоппа В.Д., Городничев Е.Н. Алгебраико-информационный подход к распознаванию образов // Труды Международной
конференции по автоматизации в геологии. М., 1990.
7. Лисенков А. Б. Выявление ведущих факторов формирования подземных
вод. М.: МГРИ,1987.
8. Сальников А.С. Распознавание золотоносных месторождений.
М.: МГРИ, 1988.
9. Харченков А.Г. Принципы и методы прогнозирования минеральных
ресурсов. М.: Недра, 1987.

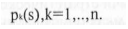
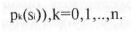
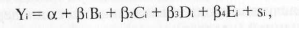
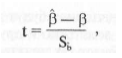
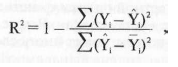
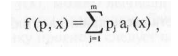

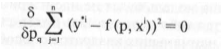
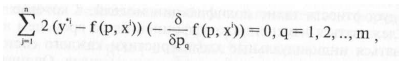
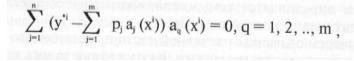
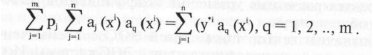
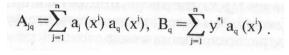
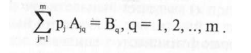
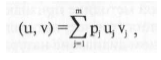

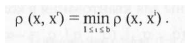
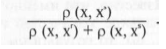



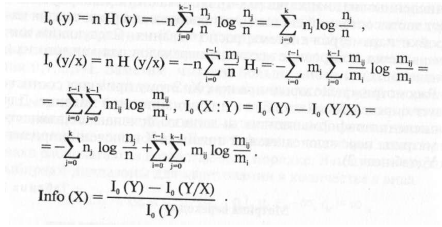
 Важное
Важное

 Важное
Важное
 Важное
Важное
 Важное
Важное